この記事は音MAD Advent Calender 2022に参加しています
こちらの企画に参加させていただけることになったので、新しくBlogを作りました。今後どんな記事を書くかは全然決めていないですが、たまに編集後記とかを残す場所にできればと思ってます。
記事の内容3行まとめ
- MAD素材の切り分けや文字起こしの作業って大変ですよね。
- なので、音声・動画の切り分けを自動でやってくれるツールを作ってみました。
- Google Colaboratoryから動かせるようにしたので使ってみてね!
とりあえず使ってみたいって人は3.使い方の章だけ見てもらえれば大丈夫です。
はじめに
初めて使うジャンルの素材で音MADを作ろうとしたときに、スターターパック的なものが用意されていると作りやすいですよね。
音声ファイルは使いやすいようにファイル名がつけてあったり、キャラごとにフォルダ分けされてあったり、よく使われる素材がまとめてあったりするので、スターターをダウンロードさえしてしまえばすぐに音声や動画の編集を始めることができます。
ただ、当然どんな素材でもスターターパックがあるなんてことはなく、むしろ用意されていない素材の方が多いくらいです。
ある程度型が決まっている素材や、CM素材のように尺が短いものであれば、元動画からそのまま音MADを作っていくことはできるかと思います。
こちらの四角さんの記事で紹介されていたような「ストーリー系MAD」みたいなものを作ろうとすると、構成をしっかり組むために大量の素材を整理する作業が必要になってきます。
自分も過去に少女終末旅行の音声素材切り分けに挑戦してみたことがあるのですが、作業が退屈すぎる&飽き性なこともあって1話分やった時点で断念しちゃいました…。
冷静に考えて、1クール分のアニメ本編=約4時間ほどの素材に対して、ちょうどいい長さで分割、セリフの文字起こしをしてファイル名をつける、発言しているキャラごとに分類する、みたいな作業をちゃんとやろうとすると平気で数日はかかります。
常人には無理だろ…って思ってたのですが、こちらの竹塔さんの記事では実際にごちうさ12話分+劇場版の音声切り分け作業をやった例が紹介されています。凄すぎる。
改めて、スターターパックを用意してくれる人には頭が上がらないですね。
そんな中、今年2022年の9月にOpen AIからWhisperという音声認識AIが発表されました。
Whisperは音声から文字起こしをやってくれるAIで、これまで存在していた音声認識ソフトとは比べ物にならない精度で音声認識ができます。
これを使えばMAD素材の音声切り分け作業がほぼ自動化できるようになるのでは…?と思い、いろいろ試してみました。
ということでこの記事では、アニメやソシャゲなど元の動画が数時間もあるような素材を使おうとした時に、素材の切り分け作業をできるだけ自動化してみようとして自分が作ったものについて紹介していきたいと思います。
いろいろと調べていく中で、音声だけじゃなくて動画の切り分けもできそうだったのでこっちも合わせてツール化してみました。
作ったものの紹介
この記事で紹介するのは以下の2つのツールです。
どちらもGoogle Colabのノートブックなので、Web上で実行することができます。
PCへのインストールや環境構築が不要ですぐ使える反面、無料版だとたまにGoogleのGPUの利用制限に引っかかることもあるのが難点です。
ローカルで動かせるツールを配布する技術力はないので許して…
1つ目は以前Twitterでも紹介したことのある文字起こしツールを改修したものです。
事前にBGM除去した音声素材を入れると、無音部分で分割した後に音声認識の結果をもとにファイル名を付けてくれます。
whisperっていう音声認識AIを使って、アニメ本編の音声からセリフごとに分割して文字起こしまで自動でできるようになった!(わたてん1話の例)
— E-tum (@E__tum) 2022年10月10日
まだ調整は必要だけど、それなりに精度は良いからこれでだいぶMAD制作のハードルが下がりそう pic.twitter.com/EwYSaOD9pM
2つ目は動画からシーンがカットされたタイミングを検出して、その部分で動画を分割するツールです。
フレーム間の画素の差分を計算して、変化が大きい部分を検出して切り分ける処理を行っています…、って言ってもイメージしづらいと思うので、試しにこちらの動画を処理にかけてみると以下のような結果になります。
↓
↓
↓
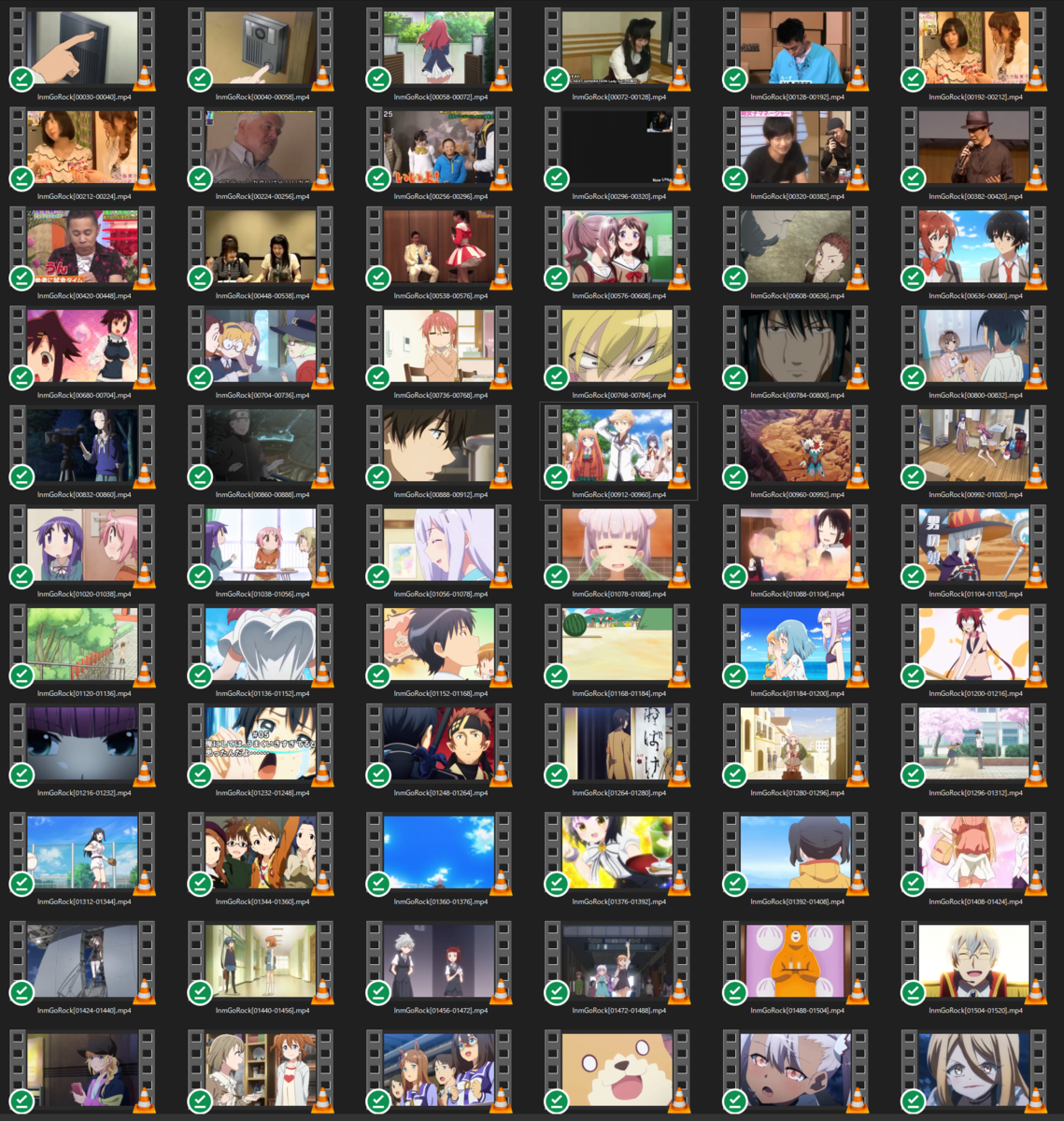
処理を実行するとこんな感じでずらーっとシーンごとに動画が出力されます。この動画自体シンプルなカット編集がメインなので、ちょうど映像が切り替わるタイミングで分割されているのがよく分かると思います。
切り分けシーンの最小秒数を0.3秒に設定していたので、最初のチャイムのシーンはつながって出力されてちゃっていますね。
これをアニメ本編の動画ファイルに対して実行すると、パッと見でどんなシーンがあるか把握できるので、映像を作るときに元の動画を開いてシークしたりする手間がかなり省けるようになります。
使い方
紹介したツールを使って、実際にアニメの本編から音声と映像の切り分けをやってみます。せっかくなので、最近流行りのぼっち・ざ・ろっく!1話を使って試してみます。
大まかな流れは下の図みたいな感じです。動画から音声を取り出してBGM除去するところまでは事前に準備が必要です。これに加えてアニメの場合はOPとED部分をカットしておくと処理時間が少し短くなります。
ソシャゲみたいにゲーム側でBGMを切って録画できる素材だと、そのまま切り分け処理できるので楽ですね。

BGM除去ができるツールはいろいろありますが、2022年12月現在ではUltimate Vocal Removerが一番精度が良いと思います。
AIボーカル除去・抽出ソフト 「Ultimate Vocal Remover」の使い方と最良設定について - YTPMV.info
Colabの環境で実行できるものも公開されていたりします。
音MAD作成支援colabノートブックを作った話【ボーカル抽出/カラオケ生成・高画質化・BB素材作成・Youtube/ニコニコダウンローダ・MIDI生成】 | FascodeNetwork Blog
音声切り分け
↓Colabノートブックのリンク↓
https://colab.research.google.com/drive/1j3L5OuPjcww0jKDkddJ4sq5QnxLeOcN8?usp=sharing(旧バージョン)
https://colab.research.google.com/drive/1UbahAgkcvpdK5Tj7lcQIfxs9ycD-L6M8?usp=sharing(faster-whisper対応版)
- Googleアカウントを用意
- Google DriveにBGM除去済みの音声ファイルを保存

- Googleアカウントにログインした状態でColabのノートブックにアクセス
ノートブックにアクセスするとこんな画面になります。こちらの方にも一応簡単な使い方は書いてあります。

- GPUを使うランタイムへの接続
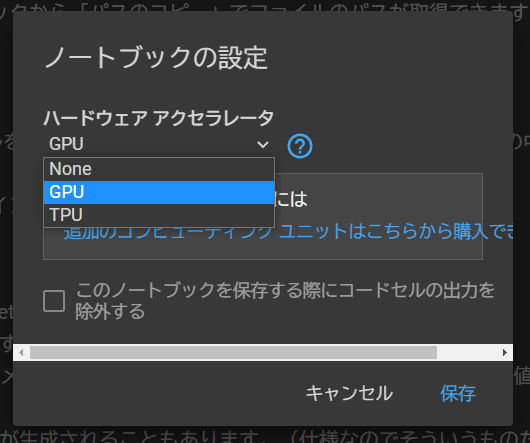
上のメニューから「ランタイム」>「ランタイムのタイプを変更」を選び、「ハードウェアアクセラレータ」が「GPU」または「TPU」になっていることを確認します。
ここが「None」になっていると処理に平気で2~3時間かかるようになってしまうので、忘れずに確認するようにしましょう(2敗)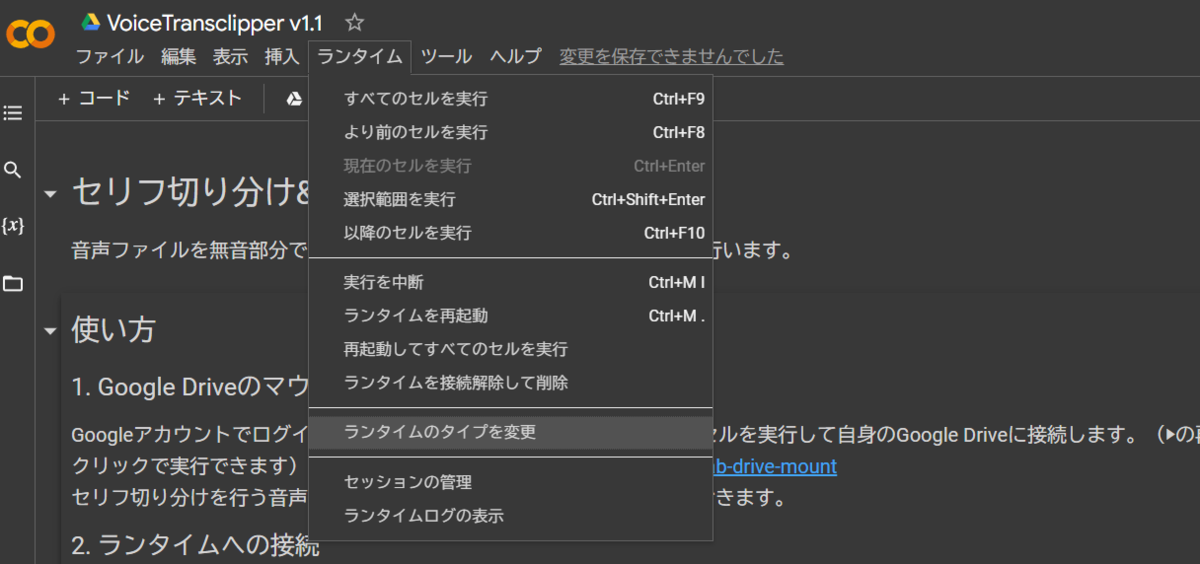
- Google Driveをマウント
「Google Driveのマウント」セルを実行して自身のGoogle Driveに接続します。(▶の再生マークをクリックで実行できます)
Google Driveのデータにアクセスするのでいくつか確認画面のポップアップが出てきます。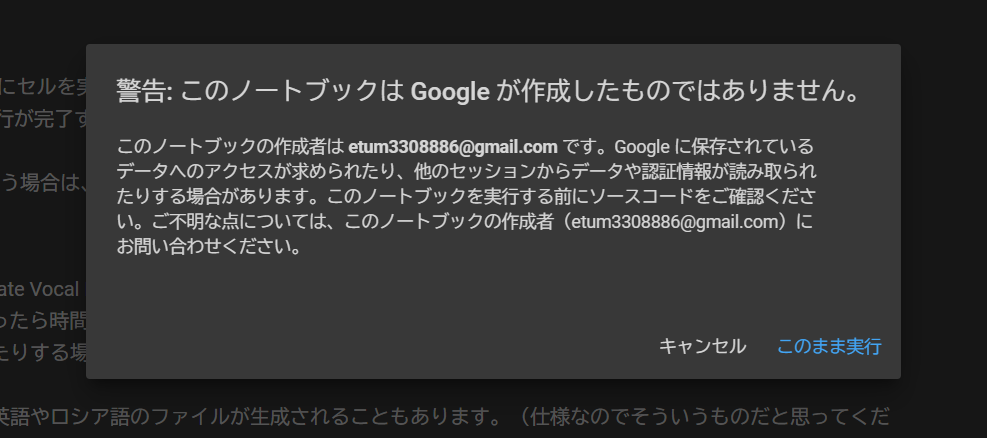
それぞれ内容を確認して先に進んでいき、以下のようにチェックマークがついたら接続完了です。

- ライブラリのインストールとモデルの読み込み(セルの実行)
「0.ライブラリのインストール」のセルを実行して、音声認識モデルの読み込みなどを行います。

- パラメータの指定(セルの実行)
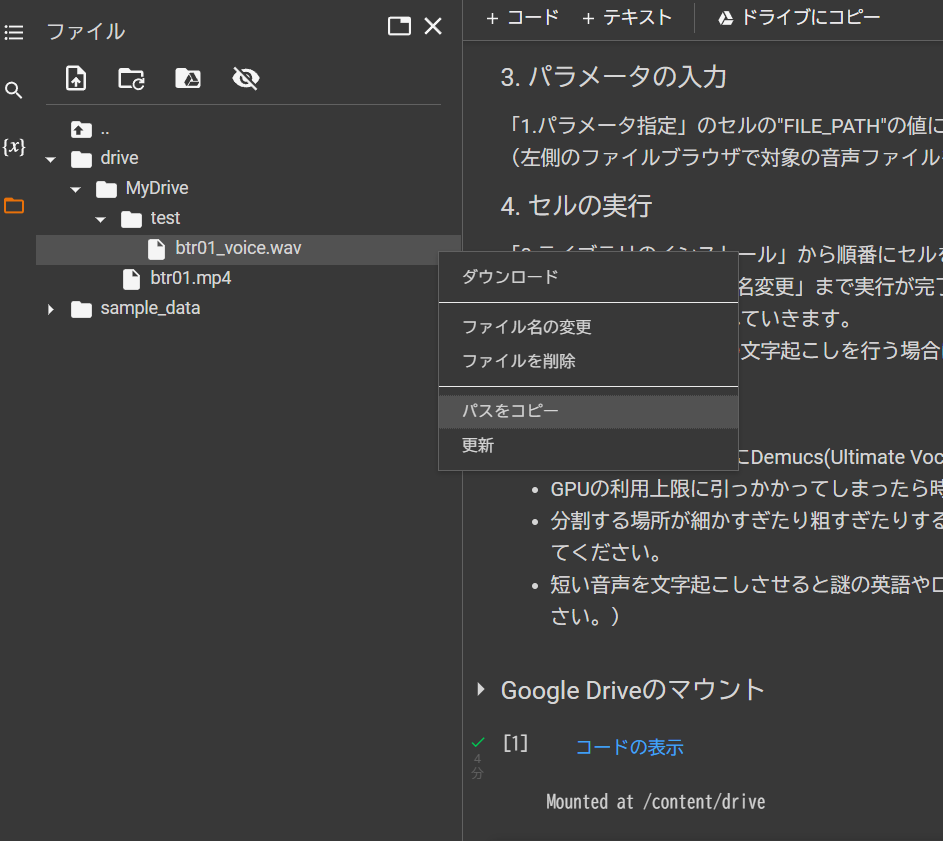
切り分け処理のパラメータを入力し、「1.パラメータ指定」のセルを実行します。
左側のファイルブラウザで対象のファイルを選択して「パスをコピー」をクリックするとファイルのパスをコピペできます。
FILE_PATH以外のパラメータは基本デフォルトのままでOKですが、切り分けの結果が微妙な時に少し調整するとうまくいくことがあります。
- 分割と文字起こし処理実行(セルの実行)
「2.音声切り分け」と「3.文字起こし&ファイル名変更」のセルを順番に実行します。(1つ目のセルを選択した後にCtrl+F10で残りのセルをまとめて実行することもできます)
ここの処理にはそこそこ時間がかかります。今回の例では15分くらいかかりました。
- 分割された音声ファイルがフォルダに保存される
全部で596個のファイルが作られました。
ところどころ誤認識はありますが、大体のセリフは見れば分かるレベルになっているかなと思います。

この時点でもある程度は使えますが、誤字の修正や長いセリフの分割、キャラごとの分類をしたい場合は、手動で整理していくことになります。
(発話者を認識するライブラリも存在するようなので、そういうのと組み合わせればこの辺の作業も自動化できそう。)
手動で整理する方法としては、REAPERにまとめて読み込み→リネームしたりキャラごとにトラック分け→アイテムを全選択して再出力、というやり方が個人的には楽かなと思います。
REAPERを使った音声ファイルの切り分け方法はこちらのたいうおさんの記事で詳しく説明されているので参考にしてみてください。
また、Google Colab上でファイルを扱うときは、基本的に自分のGoogle Driveをマウントして使うことが多いです。
Googleアカウントを持っていれば誰でも使えますが、毎回ファイルをアップロード→Colabで処理実行→分割結果をダウンロード、ってやるのは地味に面倒なので、PCの容量に余裕があればGoogle Driveのデスクトップ版をインストールしてローカルのフォルダと同期するようにしておいた方が使いやすいと思います。
雑記:Whisperの細かい話
このツールではまず音声を分割してから文字起こしという順番で処理を行っていますが、Whisper自体は数十分ある音声も読み込めるので、分割しなくても使うことはできます。
今回使った音声ファイルを分割せずに直接Whisperに読み込ませると、下の画像みたいな感じで秒数付きで台詞を表示してくれます。
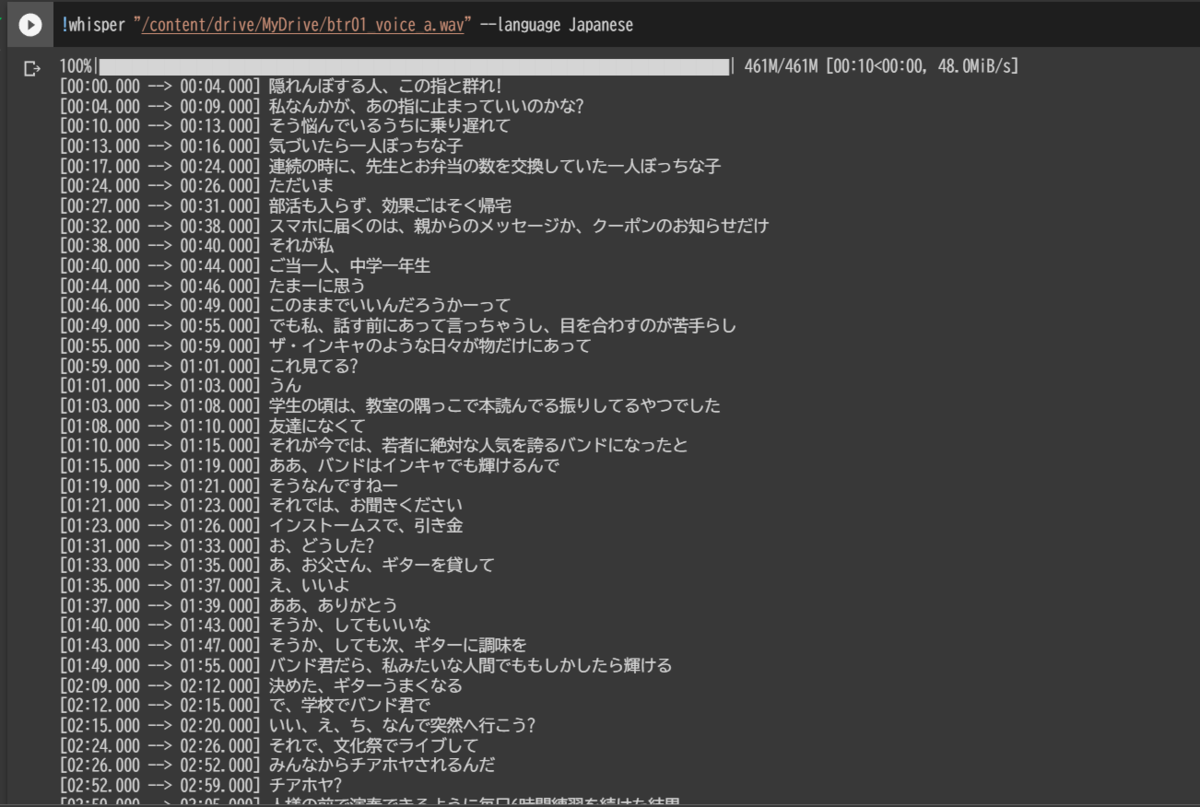
最初はこれだけで音声の分割もできるかなと思ってたんですが、実際にやってみるとどうもこの秒数の精度がかなりガバガバで上手く切り分けられなかったので、このツールでは事前に分割してから文字起こしするようにしています。
この仕様が改善されれば処理ももっと簡単で早くなるので、今後のアップデートに期待ですね。
なんかこの記事を書いてる最中にちょうどWhisperのアップデートがあったみたいです。
OpenAI Whisper Large V2 - Details & Model Comparison - YouTube
英語以外の言語の精度が上がったらしいんですが、今確認してると記事が書き終わらないので余裕ができたときにチェックしてみようと思ってます。
動画切り分け
↓Colabノートブックのリンク↓
https://colab.research.google.com/drive/1oiscGCrOvNarRXR39BGm6QXuVIAV9KjH?usp=sharing
1~6は音声切り分けのときとほぼ同じです。
- Googleアカウントを用意
- Google Driveに動画ファイルを保存
- Googleアカウントにログインした状態でColabのノートブックにアクセス

- GPUを使うランタイムへの接続(省略)
- Google Driveをマウント(省略)
- ライブラリのインストール(省略)
- パラメータの指定(セルの実行)
切り分け処理のパラメータを入力し、「1.パラメータ指定」のセルを実行します。
こっちもFILE_PATH以外のパラメータは基本デフォルトのままでOKです。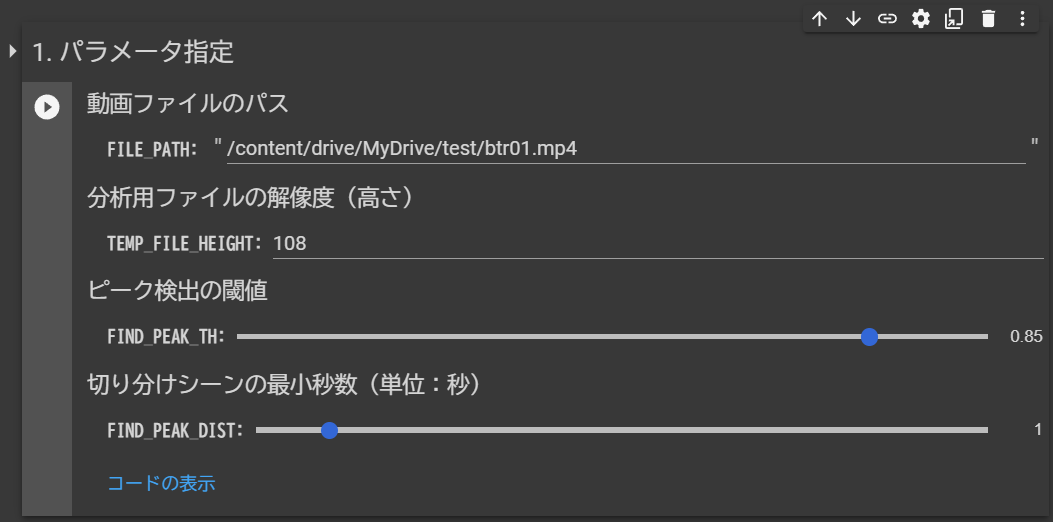
- セルを実行(動画分割)
「2.動画切り分け」のセルを実行します。
ここの処理もそこそこ時間がかかるので、ゲームでもしながらゆっくり待ちましょう。
今回は処理の途中で何度かGPU利用制限を食らったので43分かかりましたが、早い時だと10分くらいで終わることもあります。
(これが出ると悲しい)
- 分割された動画がフォルダ内に保存されます
全部で275個のファイルが作られました。元が20分35秒の動画なので、1シーンあたりだいたい4.5秒くらいですね。

雑記:プログラムの細かい話
・分析用ファイルについて
1080pの動画ファイルをそのまま読み込んでフレーム間差分を計算しようとすると確実にメモリ不足になるので、10分の1くらいに画質を落としてから処理を行っています。この分析用の動画ファイルは分割するタイミングの検出にしか使わないので、分割結果の画質には影響しないです。
分析用の動画ファイル(_108pとかがついてるやつ)がフォルダに残っちゃいますが、分割処理が終われば削除してしまって大丈夫です。(そのうち改善したい)
・変化点を検出するやり方
フレーム間の差分からシーン切り替えタイミングを検出する方法は、この記事を参考に実装しています。
計算式の細かいところはソースコードをコピペして調整しているだけなので、自分もあんまり詳しくは理解してないです。
フレーム差分を計算する都合上、激しいエフェクトがかかっている部分が細かく分割されすぎたり、逆にシーンの切り替わりがフェードで緩やかにされている場合に検出できなかったりするのが弱点です。
実際にMAD制作に使ってみた感触
最後に、自動で切り分けした素材ってMAD制作に使えるの?ってことで、実際に自分でMADを作ってみた感触について書いていきます。
今回作ったMADはこちらです。
……といいつつ、このMADで使ったのは動画切り分けの方(人力音声はほぼキャラソンボーカル)なので、音声切り分けの方についてはまだあんまり語れることがないです。
この動画のメインは人力VOCALOID、映像はおまけ(でもせっかくなら画像+音声波形みたいなの以外にしてみたい)程度に考えていたので、編集自体はAMV的なシンプルなカット編集にしつつ、その分全話の素材をできるだけ万遍なく使いたいと思っていました。
とはいえ、アニメ本編を通して見たのはかなり前で、当然MAD素材にするつもりで見ていたわけではないので、シーン探しにかかる時間短縮のため自動切り分けに頼りました。
12話分の切り分け処理にかかった時間は覚えていないですが、寝る前にまとめて切り分け処理を仕掛けておいたら次の日起きたときには全話分完了してました。
実際に切り分けてみた結果はこんな感じです。

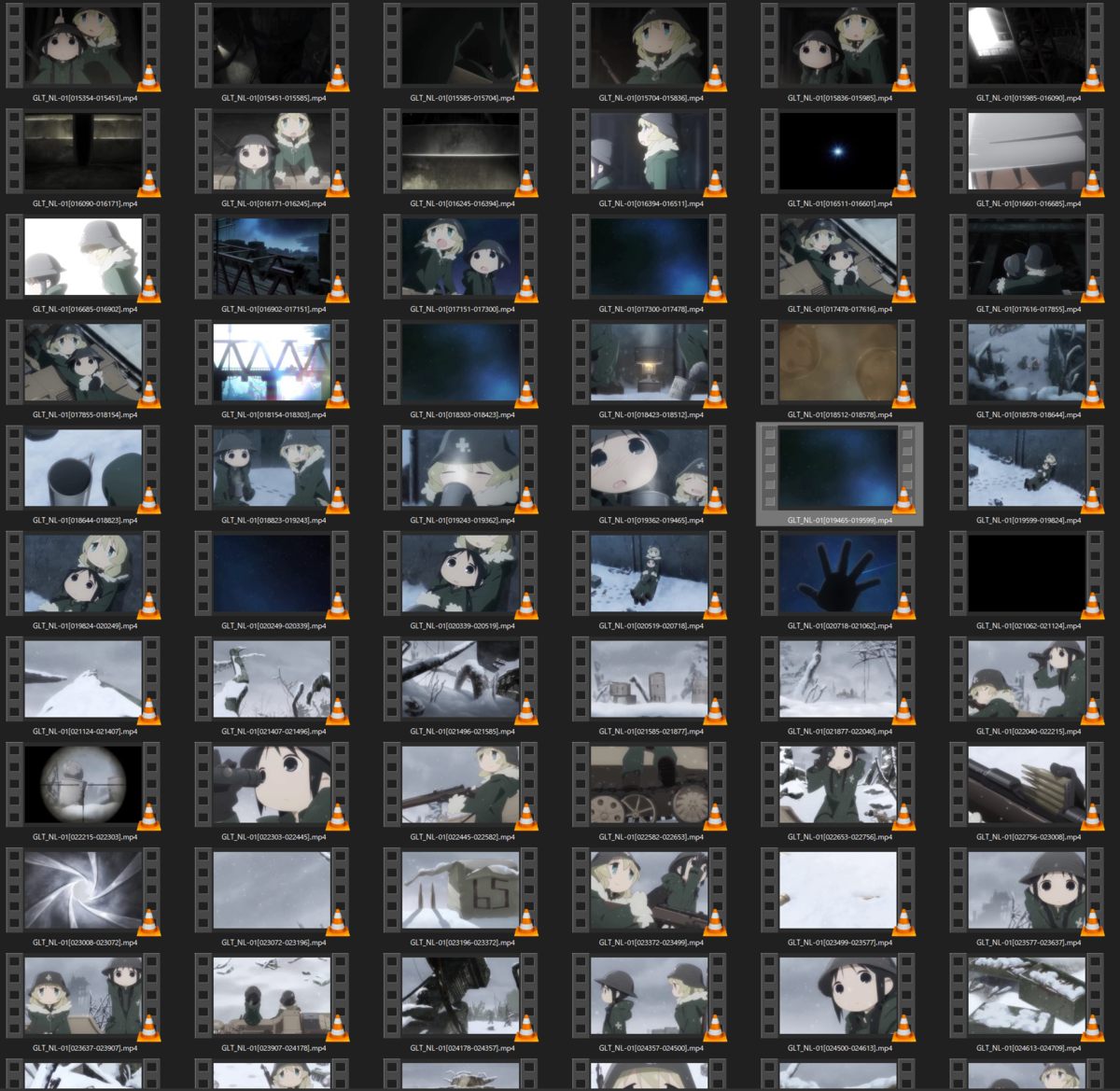
良かった点
- エクスプローラー上で動画が一覧できるので、シーンを探すのがとても楽(これが一番大きいメリット)
- ひとつひとつのファイルサイズが小さいので、編集してても重くなりにくい
- キャラの顔が映っているシーンや背景だけのシーンでまとめて分類みたいなことがやりやすい
微妙な点
- サムネで表示されないフレームにあるシーンには気付きにくい
- 素材保存用のHDDの容量が元動画と合わせて単純に2倍必要になる
- きれいに分割しきれない部分はどうしてもある
(少女終末旅行は映像的に暗いシーンが多いから変化量が小さくなりがちなのかもしれない)
最後に
ここまで読んでいただきありがとうございました。
素材の切り分けを自動化することで、それ以外の作業や構成の試行錯誤に時間を割くことができたり、動画投稿の頻度を上げることに繋がったりするのではないかと思います。
実際、自分は自動切り分けがなかったら上で紹介した動画は投稿できていなかったと思うのでかなり助かりました。
今回作ったものはColabのノートブックからソースコードも見られるので、プログラムが分かる人は好きなように改変しちゃってOKです。(むしろ改善できるならどんどんしてくれると嬉しいです)
VSTやAviUtlのスクリプトみたいなものとは違って、直接音MAD制作に役立つ機会は少ないものかもしれませんが、何か新しい素材に挑戦してみようとする人にとって少しでも助けになれればと思います。
追記(2023/02/26)
複数のファイルをまとめて処理できるようにアップデートしました。
FILE_PATHの値に音声ファイルや動画ファイルが入っているフォルダのパスを指定すると、その中のファイルをまとめて処理してくれます。
もし不具合あればコメントで教えてください。
追記(2024/02/05)
faster-whisperがColabで動かせるようになったので対応したバージョンを公開ついでに機能追加しました。使い方はほとんど変わらないですが近いうちに記事にして公開します。
https://colab.research.google.com/drive/1UbahAgkcvpdK5Tj7lcQIfxs9ycD-L6M8?usp=sharing(faster-whisper対応版)